Iterative Residual Policy
for Goal-Conditioned Dynamic Manipulation of Deformable Objects
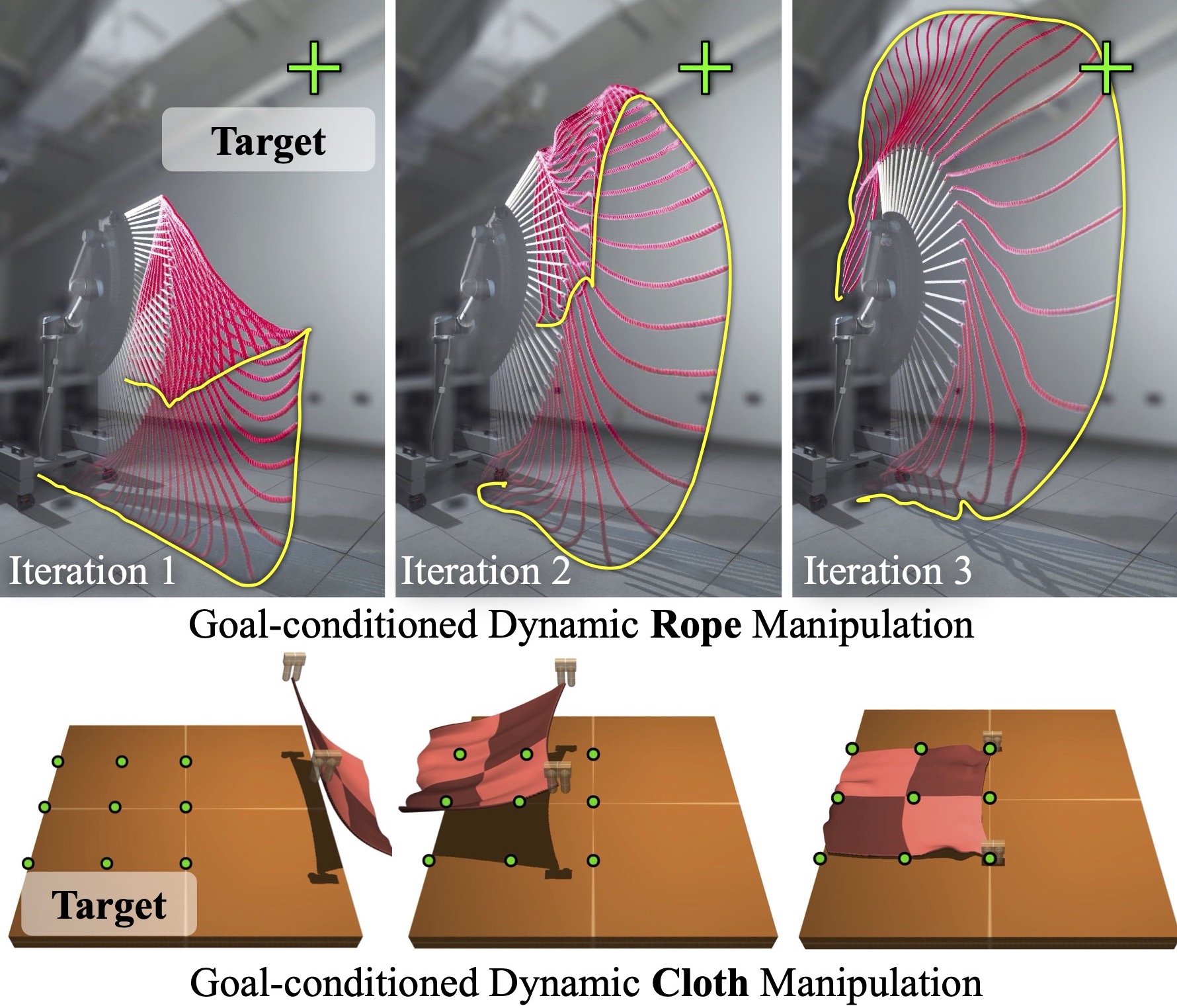
This paper tackles the task of goal-conditioned dynamic manipulation of deformable objects. This task is highly challenging due to its complex dynamics (introduced by object deformation and high-speed action) and strict task requirements (defined by a precise goal specification). To address these challenges, we present Iterative Residual Policy (IRP), a general learning framework applicable to repeatable tasks with complex dynamics. IRP learns an implicit policy via delta dynamics -- instead of modeling the entire dynamical system and inferring actions from that model, IRP learns delta dynamics that predict the effects of delta action on the previously-observed trajectory. When combined with adaptive action sampling, the system can quickly optimize its actions online to reach a specified goal. We demonstrate the effectiveness of IRP on two tasks: whipping a rope to hit a target point and swinging a cloth to reach a target pose. Despite being trained only in simulation on a fixed robot setup, IRP is able to efficiently generalize to noisy real-world dynamics, new objects with unseen physical properties, and even different robot hardware embodiments, demonstrating its excellent generalization capability relative to alternative approaches.
Paper
Latest version: arXiv:2203.00663 [cs.RO] or here.
Robotics: Science and Systems (RSS) 2022
★ Best Paper Award, RSS ★
★ Best Student Paper Award Finalist, RSS★

Code
Code and instructions to download data: Github
Team





Bibtex
@inproceedings{chi2022irp,
title={Iterative Residual Policy for Goal-Conditioned Dynamic Manipulation of Deformable Objects},
author={Chi, Cheng and Burchfiel, Benjamin and Cousineau, Eric and Feng, Siyuan and Song, Shuran},
booktitle={Proceedings of Robotics: Science and Systems (RSS)},
year={2022}
}
Technical Summary Video (with audio)
Task and Challanges
We study the task of goal-conditioned dynamic manipulation of deformable objects, examples of which include whipping a target point with the tip of a rope or spreading a cloth into a target pose. This task is highly challanging due to:
(1) Complex object physical property and dynamics
(2) Large Sim2Real gap
Rope Whipping Task Results
Despite these challanges, our method (IRP) is able to generalize to wide variety of ropes on a real robot system, all with a single model trained entirely using simulation data.
Hitting Real Targets
Online Adaptaiton
To demostrate the robustness of our method against unexpected system changes, we tie several konts after step 6, completely chainging the rope's physical property. Due to our iterative formulation, IRP is quickly adapts and regain good performance.
Cloth Placement Task Results
To demostrate the generality of our method, we directly applied IRP on a cloth placement task. This video shows 2 typical strategies learned by IRP.
Acknowledgements
The authors would like to thank Zhenjia Xu, Huy Ha, Dale McConachie, Naveen Kuppuswamy for their helpful feedback and fruitful discussions. This work was supported by the Toyota Research Institute, NSF CMMI-2037101 and NSF IIS-2132519. We would like to thank Google for the UR5 robot hardware. The views and conclusions contained herein are those of the authors and should not be interpreted as necessarily representing the official policies, either expressed or implied, of the sponsors.
Contact
If you have any questions, please feel free to contact Cheng Chi